Apache Spark Internals: Executor launch orchestration
Here I explain how executors are gets launched when a Spark application starts up. Assumption is that Master and one Worker is already up and running with one Driver application.
Below is an example of a command line that we normally use to start a Driver app.
./bin/spark-shell --executor-cores 2 --executor-memory 1G --master spark://192.168.1.100:7077
Spark context Web UI available at http://192.168.1.20:4040
Spark context available as 'sc' (master = spark://192.168.1.100:7077, app id = app-20221217200505-0004).
Spark session available as 'spark'.
...
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0-SNAPSHOT
/_/
Here we start spark shell and set required resources for application in terms of CPU cores and memory, then we set our Master URL to connect to.
Driver (SparkSession and SparkContext inside our spark-shell) is then starts up all important Driver components like DagScheduler, TaskScheduler and SchedulerBackend.
- DagScheduler - it is responsible for creating stages and resolving dependencies between them. It also creates tasks and packages them as TaskSets
- TaskScheduler - manages TaskSets and responsible for rescheduling them on the backend.
- SchedulerBackend - responsible for requesting Executors or removing/killing them etc. and it holds an RPC client (AppClient through RPCEnv - see next) and defines /Driver endpoint to communicate directly with Executors during run.
- SparkEnv - This is a container that holds key set of components like MapOutputTracker, ShuffleManager, BroadcastManager, BlockManager. These are used handle (shuffle, broadcast etc.) data blocks across cluster during application execution. It also holds RPCEnv which is an RPC server that publishes endpoints to communicate with rest of the cluster i.e. Master for Executor registration and with Executors to get and provide various statuses of the application execution.
Below picture depicts in detail how a driver start up process go about launching executor requested by user.
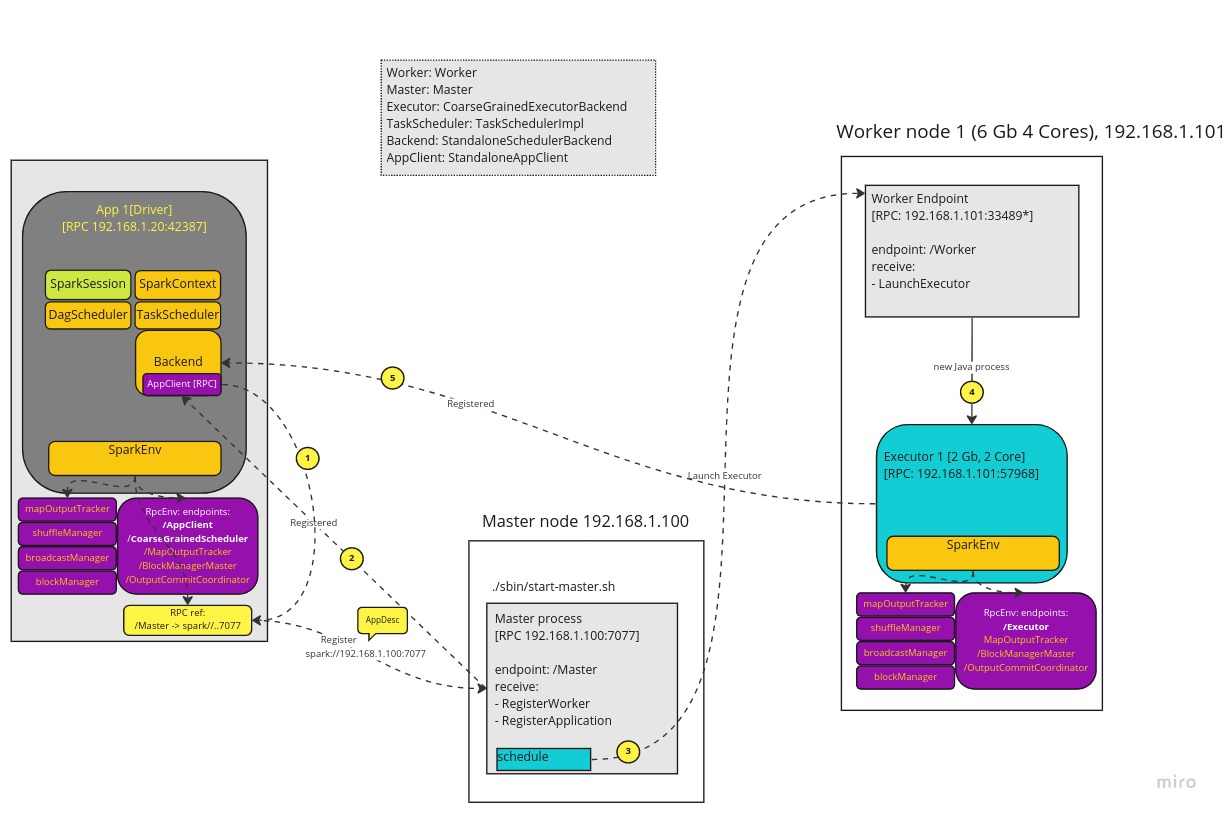
Start up flow
During app startup BackendScheduler send an RegisterApplication RPC request to Master in the form of ApplicationDescription. Master send acknowledgement response about that once done.
Then Master continues and allocates worker resources to Executors for the given application. Then it send LaunchExecutor RPC request to Worker node and that creates a new Java process for given Executor. This is done for each worker depending on how much resources were requested from a driver. Finally, once Executor is launched it sends registration request to Driver endpoint and driver adds that into available Executors list for application execution.
Although, this description is mouthful the process happens instantly in practice. And driver gets it’s executors ready in few seconds.
Summary
Hopefully, this brief info gives you some idea how Driver gets its executors and how communication happens between Driver, Master, Worker and Executor.